")
Joe Zhou, responsable des relations auprčs des développeurs chez JuiceData, nous a présenté les derničres fonctionnalités de JuiceFS. (Crédit P.K.)
Conçu pour s'appuyer sur le stockage objet comme backend universel, JuiceFS de JuiceData s'impose progressivement comme une alternative crédible aux systčmes de fichiers distribués traditionnels dans les pipelines d'entraînement de modčles IA.
Le stockage objet s'est imposé comme le backend de référence des infrastructures modernes : scalabilité quasi illimitée, durabilité extręme (onze neuf de disponibilité chez AWS S3), accčs multi-régions et coűt plancher d'environ deux centimes par gigaoctet et par mois. Mais pour les développeurs et les équipes data, travailler directement avec ces ressources reste ardu : pas de mise ŕ jour en place, pas de hiérarchie de répertoires, des opérations de métadonnées coűteuses et une latence structurellement plus élevée qu'un systčme de fichiers local. C'est précisément ces lacunes que JuiceFS de JuiceData cherche ŕ combler. "L'idée originelle de JuiceFS était de remplacer HDFS pour constituer une fondation unifiée pour le stockage de fichiers. Mais c'est parce que les frameworks Python de machine learning travaillent nativement avec des fichiers - et qu'ŕ l'heure de l'IA, les données d'entraînement atteignent l'échelle du pétaoctet - que JuiceFS aide ces workloads ŕ tourner en mode distribué de façon beaucoup plus fluide", explique Joe Zhou, responsable des relations auprčs des développeurs chez JuiceData, lors d'une présentation ŕ Boston en juin 2026 dans le cadre d'un IT Press Tour.
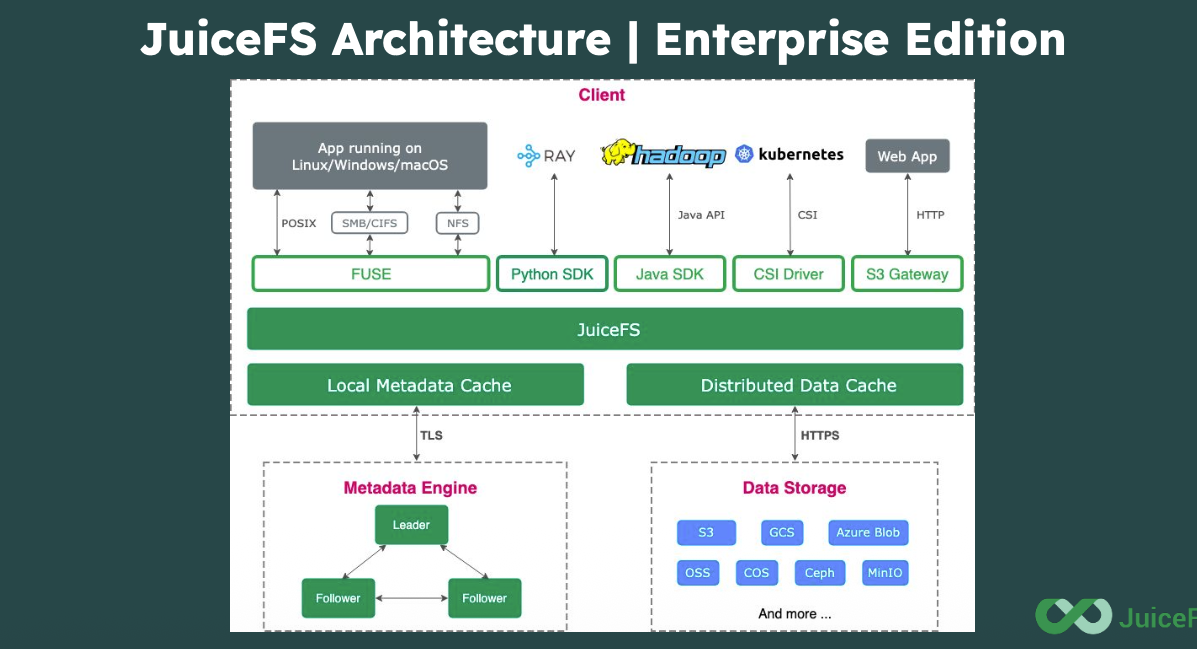
Sur le plan architectural, JuiceFS repose sur une séparation stricte entre le plan de métadonnées et celui des données. Le moteur de métadonnées (un moteur transactionnel dédié dans l'édition Enterprise, ou une base de données généraliste comme Redis, TiKV ou PostgreSQL dans la Community Edition) est totalement indépendant du backend objet. Les fichiers, eux, sont découpés en blocs de quatre mégaoctets maximum avant d'ętre poussés sur n'importe quel object store compatible S3, Azure Blob ou GCS. Ce chunking est la clé de voűte du systčme : lŕ oů S3 Files d'AWS doit réécrire l'intégralité d'un objet pour modifier quelques octets ŕ la fin d'un fichier, JuiceFS ne touche qu'au bloc concerné.
DFS ou PFS : une frontičre qui s'estompe
Dans un DFS, chaque fichier est stocké sur un noeud (ou répliqué sur plusieurs), et les clients y accčdent via le réseau - mais un seul flux de données alimente un fichier ŕ la fois. La scalabilité est horizontale sur le nombre de fichiers, pas sur le débit d'accčs ŕ un fichier unique. Un PFS comme Lustre ou WekaFS fonctionne différemment : un męme fichier est physiquement découpé en bandes (stripes) réparties sur plusieurs noeuds de stockage (OSS/OST dans la terminologie Lustre). Plusieurs clients peuvent ainsi lire ou écrire simultanément des régions différentes d'un męme fichier, chacun s'adressant directement au noeud qui détient sa bande. Pour arbitrer ces accčs concurrents sans corruption, le systčme maintient des verrous ŕ grain trčs fin - c'est-ŕ-dire des verrous portant non pas sur le fichier entier, mais sur des intervalles d'octets précis (byte-range locks). Un client peut ainsi détenir un verrou en lecture sur les octets 0-512 Mo pendant qu'un autre écrit les octets 512 Mo - 1 Go, le tout sans contention. C'est cet avantage structurel qui compte pour les workloads d'entraînement de LLM : lire un checkpoint de plusieurs centaines de gigaoctets ŕ pleine bande passante agrégée depuis des dizaines de noeuds GPU simultanément est un cas d'usage pour lequel les PFS ont été explicitement conçus, et oů JuiceFS - architecturé comme un DFS cloud-native avec séparation données/métadonnées - ne peut pas rivaliser nativement avec le męme niveau de parallélisme intra-fichier.
Pour les entreprises souhaitant déployer JuiceFS dans leur propre datacenter, JuiceData propose une version on-premise de l'Enterprise Edition. (Crédit P.K.)
JuiceFS est donc fondamentalement un DFS cloud-natif : pour garantir la cohérence des données, il s'appuie sur un moteur de métadonnées transactionnel - et non sur des mécanismes de verrouillage fin au niveau de chaque fichier comme le fait Lustre. Dans un PFS comme Lustre, chaque noeud peut verrouiller une petite portion d'un fichier (un « grain fin ») pour permettre des écritures concurrentes ŕ trčs haute vitesse. JuiceFS, lui, délčgue toute la gestion de la cohérence ŕ son moteur de métadonnées, qui joue le rôle d'arbitre centralisé via des transactions - une approche plus simple ŕ opérer en environnement cloud, mais moins optimale pour les accčs parallčles intensifs ŕ un męme fichier. Son parallélisme découle naturellement du découpage en blocs stockés sur un object storage, ce qui permet ŕ plusieurs clients de lire et écrire en parallčle sur des fichiers différents, voire sur différents blocs d'un męme fichier. Toutefois, la frontičre entre DFS et PFS devient de plus en plus ténue avec des solutions modernes comme CephFS ou WekaFS, qui brouillent les catégories en combinant distribution (scalabilité, réplication) et capacités parallčles (striping par fichier, accčs concurrent ŕ haute bande passante). Joe Zhou reconnaît d'ailleurs la concurrence directe : "Oui, nous sommes en compétition directe avec Lustre, WekaFS, GPFS et des systčmes similaires. Un POC dira souvent s'il y a ou non un bon résultat." L'approche de JuiceData mise davantage sur la flexibilité, l'élasticité du cloud et la réduction des coűts opérationnels que sur la performance brute en bande passante séquentielle. La séparation métadonnées/données évite de faire transiter les données par l'infrastructure JuiceData elle-męme : "Vous ne payez que les coűts de transfert de l'object store que vous utilisez. Nous ne relayons pas ce trafic - les deux plans sont complčtement séparés", souligne le responsable.
Les nouveautés annoncées ŕ Boston
Côté Community Edition, JuiceData a présenté une fonctionnalité de tiering de stockage par classes S3 directement pilotable depuis la CLI. Il devient possible de mapper des répertoires ou męme des fichiers individuels vers des classes de stockage spécifiques (Standard-IA, Intelligent-Tiering, Glacier Instant Retrieval) via de simples commandes de configuration. Une nouveauté significative, ŕ tel point que Joe Zhou précise qu'elle a été implémentée ŕ la demande de la communauté open source avant męme d'ętre portée sur l'édition Enterprise : "Cette fonctionnalité de tiering n'est pas encore dans l'édition Enterprise, mais elle est si intéressante que nous allons progressivement la porter depuis la Community Edition."
Pour l'édition Enterprise, l'annonce majeure porte sur le franchissement du seuil des 500 milliards de fichiers dans un seul volume. En juin 2025, des clients avaient atteint les 100 milliards de fichiers, jusqu'alors limite implicite du systčme. Les équipes ont conduit une campagne d'optimisation intensive pour valider 500 milliards en environnement de test, avec une trajectoire vers les 1 000 milliards. L'autre fonctionnalité phare reste le Mirror File System, disponible en deux variantes : le mode cache-only (seules les métadonnées sont répliquées vers la région miroir, avec un groupe de cache distribué pour les données chaudes) et le mode full mirror (métadonnées et object store entičrement répliqués). La société MiniMax, l'un des acteurs majeurs de l'IA générative en Chine, utilise déjŕ le mode cache-only avec une région source et plusieurs régions miroir pour alimenter ses GPU répartis géographiquement, et envisage de passer au full mirror.
JuiceData, fort d'une équipe d'une trentaine ŕ quarante-cinq personnes majoritairement basées en Chine, affiche déjŕ la rentabilité et compte plusieurs centaines de déploiements Enterprise ŕ l'échelle mondiale, dont certains ŕ des volumes de l'ordre du pétaoctet.














Suivez-nous