")
Pour Swami Sivasubramanian, vice-président des données et de l’IA chez AWS, « l'annonce d'aujourd'hui est une étape majeure qui met l'IA générative ŕ la portée de toutes les entreprises ». (Crédit : AWS)
Face ŕ une concurrence de plus en plus forte, AWS accélčre dans le domaine de l'IA. La firme vient en effet d'annoncer la disponibilité générale de Bedrock avec des modčles d'IA supplémentaires, ainsi que la personnalisation de CodeWhisperer. Titan et QuickSight profitent également de cette vague d'améliorations.
AWS multiplie les annonces autour de l'intelligence artificielle et plus exactement l'IA générative. En début de semaine, Amazon - maison-mčre d'AWS - a annoncé des investissements pouvant grimper jusqu'ŕ 4 Md$ dans Anthropic. Aujourd'hui, la firme dévoile donc un autre paquet d'innovations en la matičre. Le point phare est évidemment la disponibilité générale de Bedrock. Annoncé en avril, ce service entičrement géré rend disponibles les modčles de base (dit de fondation) des principales sociétés d'IA via une API unique. Pour rappel, les FM sont de trčs grands modčles d'apprentissage automatique pré-entraînés sur de grandes quantités de données. Facilement applicables ŕ un large éventail de cas d'utilisation du fait de leur flexibilité, ils sont toutefois souvent la cause de points de blocages pour les entreprises.
Premičrement, il y a le besoin d'un moyen simple de trouver et d'accéder ŕ des LLM performants, qui donnent des résultats ŕ la hauteur et qui sont les mieux adaptés ŕ leurs objectifs. Deuxičmement, les clients souhaitent que l'intégration des applications soit transparente, sans gérer d'énormes clusters d'infrastructures ni engager de coűts élevés. Enfin, ils cherchent des moyens simples pour les utiliser et créer des applications différenciées avec leurs données. Cependant, au vu de l'importance de ces données, il y a un besoin de contrôler la maničre dont elles sont partagées et utilisées. AWS indique qu'avec Bedrock, les utilisateurs n'ont plus ŕ se soucier de ce type de problčme. En outre, la solution offre des capacités différenciées telles que la création d'agents managés qui exécutent des tâches métiers complexes - de la réservation de voyages et du traitement des réclamations d'assurance ŕ la création de campagnes publicitaires et ŕ la gestion de l'inventaire - sans écrire de code.
Llama 2 de Meta arrive sur Bedrock
Le moins que l'on puisse dire c'est que AWS a (enfin) compris l'intéręt de l'IA générative et met désormais un coup d'accélérateur en la matičre, comme le confirme Swami Sivasubramanian, vice-président des données et de l'IA chez AWS. « Au cours de l'année écoulée, la prolifération des données, l'accčs ŕ un calcul évolutif et les avancées en matičre d'apprentissage automatique ont entraîné un regain d'intéręt pour l'IA générative, suscitant de nouvelles idées susceptibles de transformer des secteurs entiers et de réimaginer la façon dont le travail est effectué », a-t-il déclaré. Et d'ajouter que : « L'annonce d'aujourd'hui est une étape majeure qui met l'IA générative ŕ la portée de toutes les entreprises, quelle que soit leur taille, et de tous les employés, des développeurs aux analystes de données ».
En conséquence, AWS a fait le choix de connecter son service Bedrock ŕ une sélection de LLM de premier plan, incluant les modčles d'AI21 Labs, Anthropic, Cohere, Stability AI, et dans les prochaines semaines, Meta. La firme précise que « Bedrock est le premier service d'IA générative entičrement géré ŕ offrir Llama 2, derničre génération de LLM de Meta, par le biais d'une API ». Les clients pourront donc créer des applications d'IA générative alimentées par les modčles Llama 2 ŕ 13B et 70B paramčtres, sans avoir besoin de configurer et de gérer une quelconque infrastructure. Pour mémoire, ces modčles disposent d'améliorations significatives par rapport aux modčles Llama d'origine, avec un entraînement sur 40 % de données supplémentaires et un contexte plus long de 4 000 tokens pour travailler avec des documents plus volumineux.
CodeWhisperer prend de la hauteur avec l'IA
Formé sur des milliards de lignes de code Amazon et public, CodeWhisperer est souvent présenté comme un assistant ŕ base d'IA qui améliore la productivité des développeurs. Si ces derniers utilisent fréquemment l'outil pour leur travail quotidien, ils ont parfois besoin d'incorporer la base de code interne et privée de leur entreprise (par exemple, les API internes, les bibliothčques, les paquets et les classes) dans une application, dont aucune n'est incluse dans les données d'entraînement de CodeWhisperer. Et parmi les problčmes rencontrés, il y a notamment la difficulté ŕ utiliser ce code interne car la documentation peut ętre limitée et il n'y a pas de ressources publiques ou de forums oů les développeurs peuvent demander de l'aide.
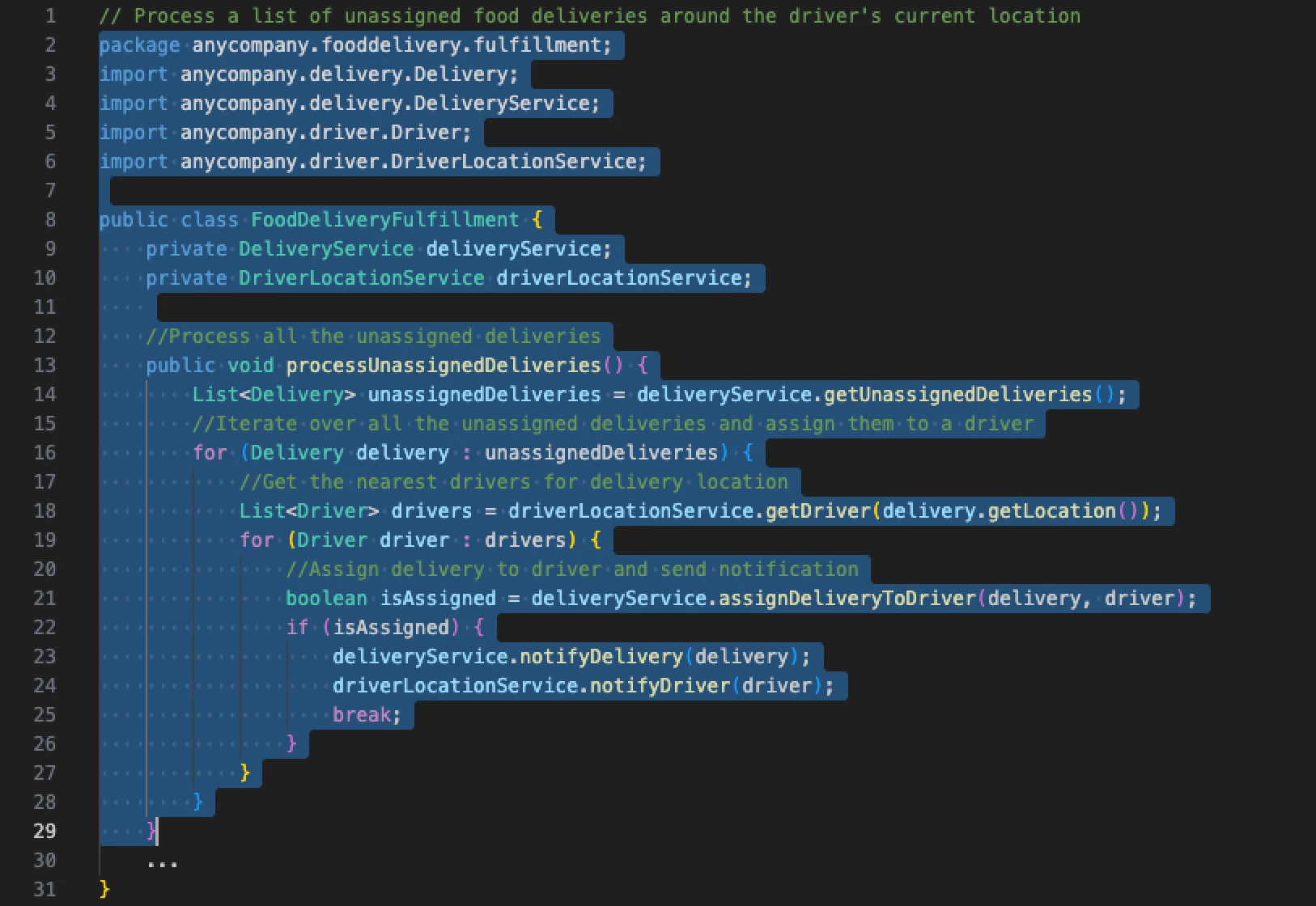
Un exemple des capacités de personnalisation de CodeWhisperer. (Crédit : AWS)
En ce sens, la capacité de personnalisation ajoutée ŕ CodeWhisperer doit aider les utilisateurs dans la personnalisation des suggestions en utilisant leur base de code privée dans un environnement sécurisé. Pour se faire, AWS indique qu'il suffit qu'un administrateur se connecte ŕ son dépôt de code privé ŕ partir d'une source, telle que GitLab ou S3, et planifie une tâche pour créer sa propre personnalisation. A noter que, dans un souci de sécurité, le LLM sous-jacent qui alimente CodeWhisperer n'utilise pas les personnalisations pour la formation. Cette capacité de personnalisation sera disponible en preview pour les clients dans les prochaines semaines, dans le cadre d'une prochaine version de CodeWhisperer Enterprise Tier, est-il précisé.
D'autres changements mineurs avec Titan et QuickSight
En complément de cette vague de changements, AWS a annoncé que Titan Embeddings est désormais disponible de maničre générale. Pour rappel, Titan Embeddings fait partie d'une famille de modčles - Titan FM - créés et pré-entraînés par AWS sur de grands ensembles de données, ce qui en fait des capacités puissantes et générales conçues pour prendre en charge une variété de cas d'utilisation. Le premier de ces modčles généralement mis ŕ la disposition des clients est donc Titan Embeddings, un LLM qui convertit le texte en représentations numériques appelées embeddings pour alimenter les cas d'utilisation de Retrieval-Augmented Generation (RAG ou génération augmentée de récupération).
De son côté, QuickSight dispose de capacités supplémentaires de création de Business Intelligence (BI). Avec, les experts peuvent créer et personnaliser facilement des visuels ŕ l'aide de commandes en langage naturel (par exemple, « quels sont les 10 produits les plus vendus en Californie ? » ou avec des fragments de question « top 10 produits »). Les analystes métiers décrivent simplement le résultat souhaité et QuickSight génčre des visuels qui peuvent ętre facilement ajoutés ŕ un tableau de bord ou ŕ un rapport en un seul clic.









Suivez-nous