")
Directeur architecture chez AMD, Kurtis Bowman pilote également le consortium UALink poru contre la domination de Nvidia sur les clusters de GPU. (Crédit S.L.)
Le consortium UALink, soutenu par AMD, HPE, Intel, Meta, Microsoft et d'autres géants du secteur, présente une alternative ouverte au protocole NVLink de Nvidia pour créer des clusters IA avec des centaines d'accélérateurs - GPU et autres - connectés dans les centres de données.
Lors d'un IT Press Tour dans la Silicon Valley début juin, l'équipe pilotant le consortium UALink nous a détaillé - dans les locaux d'AMD ŕ Santa Clara - les ambitions et les spécifications techniques de son protocole d'interconnexion destiné ŕ relier efficacement des centaines d'accélérateurs (GPU, TPU...) au sein de clusters pour l'intelligence artificielle et le calcul haute performance (HPC). Cette initiative vise ŕ répondre ŕ la demande croissante d'un standard ouvert, alors que le marché est aujourd'hui largement dominé par NVLink, la solution propriétaire de Nvidia.
Un consortium industriel aux membres variés
UALink réunit plus de 100 acteurs issus de différents horizons technologiques. Parmi les membres du conseil d'administration figurent AMD, Intel, Meta, Microsoft, Google, AWS, Cisco, Synopsys, HPE, Alibaba et Apple. Cette diversité reflčte la volonté d'adresser un besoin transversal, comme le souligne Kurtis Bowman, président du consortium UALink et directeur architecture chez AMD : « L'un des principaux intéręts pour les membres, c'est de pouvoir s'appuyer sur une infrastructure commune, quels que soient les fournisseurs d'accélérateurs, afin de simplifier la gestion et la maintenance des clusters ». Il faut toutefois noter l'absence remarquée de Dell Technologies parmi les membres, alors que d'autres fournisseurs clefs et des hyperscalers participent activement au projet. Cette situation s'explique, selon le consortium, par une stratégie d'attente de la part de Dell, qui souhaite observer les premiers déploiements industriels avant de s'engager.

On retrouve des poids lourds comme AMD, Intel, HPE dans le consortium UALink, mais pas encore Dell Technologies ou Arista Networks. (Crédit S.L.)
Spécifications techniques d'UALink 200G 1.0
La premičre version du protocole, UALink 200G 1.0, a été publiée en avril 2025. Elle s'appuie sur une architecture en pods pouvant regrouper jusqu'ŕ 1 024 accélérateurs interconnectés via des switches UALink dédiés. Chaque port de switch offre une bande passante de 800 Gb/s, avec une latence de l'ordre de 2 microsecondes, adaptée aux exigences des modčles IA de grande taille.
Le protocole UALink repose sur plusieurs couches fonctionnelles :
- Une couche physique dérivée du standard Ethernet 802.3, permettant de réutiliser câbles, connecteurs et retimers déjŕ largement déployés dans les datacenters ;
- Une couche data link qui regroupe les données en paquets de 640 octets, avec un taux d'efficacité de plus de 98 % grâce ŕ une gestion optimisée des en-tętes et du contrôle d'erreur ;
- Une couche transactionnelle qui simplifie la gestion des accčs mémoire directs (lecture, écriture, opérations atomiques) entre accélérateurs, en maintenant la cohérence logicielle sans complexifier l'architecture matérielle ;
- Un modčle de routage basé sur des identifiants permettant de partitionner un pod en sous-groupes virtuels, chaque accélérateur étant adressé de maničre unique.
Nathan Kalyanasundharam, Corporate Fellow chez AMD et responsable technique du consortium, nous a précisé : « Nous avons voulu un protocole simple, efficace en surface silicium et en consommation énergétique, qui ne nécessite pas de mécanismes de contrôle complexes d'un bout ŕ l'autre. Cela permet de réduire la consommation liée ŕ la communication, qui devient significative ŕ l'échelle de plusieurs centaines de GPU ».

Les pods UALink reposent sur des liens Ethernet au-delŕ de quatre noeuds. (Crédit S.L.)
Un contexte concurrentiel en mouvement
UALink propose une gestion flexible des switches, avec des modčles proches de l'Ethernet pour la configuration, la télémétrie et la résilience. La sécurité n'est pas oubliée : la fonction UALinkSec permet de chiffrer et d'authentifier les échanges entre accélérateurs, notamment dans des environnements multi-locataires ou de calcul confidentiel. L'architecture privilégie le scale-up (l'agrégation d'accélérateurs dans un męme pod), mais prévoit aussi le scale-out via l'interconnexion de plusieurs pods par Ethernet classique, afin de construire des clusters de plusieurs milliers de GPU.
L'arrivée de UALink intervient alors que le marché est fortement structuré autour de NVLink, la technologie propriétaire de Nvidia. Face ŕ cette initiative ouverte, la firme a récemment annoncé l'ouverture partielle de son protocole via le programme Fusion, permettant ŕ certains partenaires d'intégrer NVLink dans leurs propres solutions, tout en conservant un contrôle étroit sur l'écosystčme. « L'ouverture de NVLink est une réaction directe ŕ l'émergence de standards ouverts comme UALink. Mais notre approche vise ŕ offrir davantage de flexibilité et ŕ réduire les coűts d'acquisition et d'exploitation pour les opérateurs de datacenters », analyse Kurtis Bowman. Tandis que Nathan Kalyanasundharam précise : « L'un des objectifs majeurs [d'UALink] est de faciliter l'intégration logicielle, en travaillant avec les principaux frameworks IA pour que l'utilisation de la mémoire partagée entre accélérateurs soit transparente pour les développeurs ».
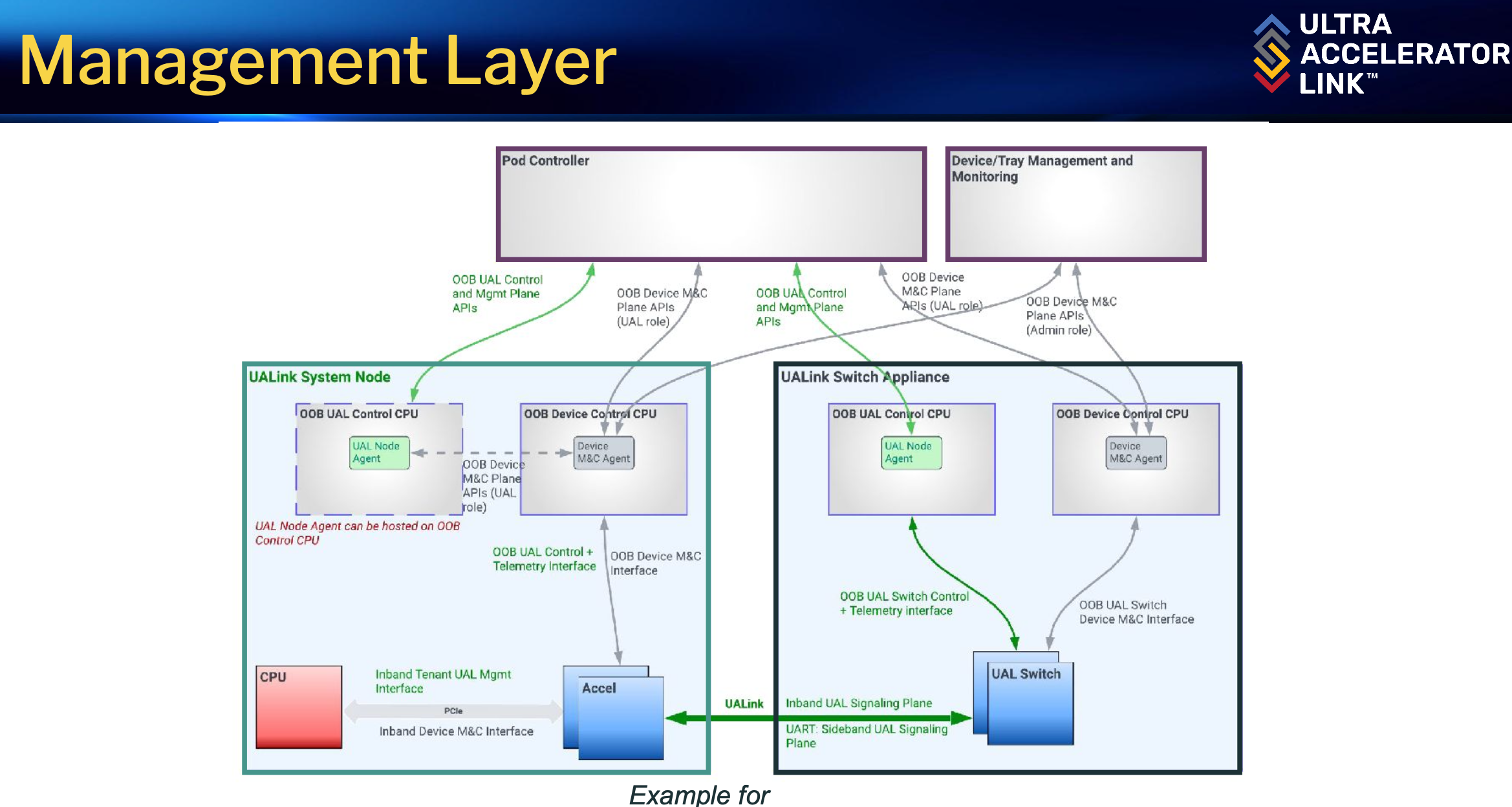
La gestion des pods dans un cluster est des éléments clefs d'UALink. (Crédit S.L.)
Perspectives et prochaines étapes
Le consortium prévoit la disponibilité des premiers composants compatibles UALink dčs 2026, avec une forte implication des fournisseurs de silicium et des hyperscalers dans la phase de validation et de déploiement. Plusieurs évolutions sont déjŕ ŕ l'étude, notamment l'intégration de l'optique pour étendre la portée des interconnexions ou l'ajout de fonctions collectives dans les switchs. UALink s'inscrit dans une logique de standardisation et d'ouverture, avec l'ambition de faciliter l'accčs ŕ des infrastructures d'IA et de HPC plus flexibles et économiquement maîtrisées. Le projet bénéficie d'un large soutien industriel, mais son adoption ŕ grande échelle dépendra de la capacité du consortium ŕ maintenir la simplicité du protocole tout en répondant aux besoins croissants du marché.














Suivez-nous