
Cloudera s’appuie toujours sur l’open source pour accompagner aussi bien les migrations que la fédération de systčmes existants.
Sur un marché de l'hébergement des données en pleine mutation (data warehouse, data lake house et autres data store, Cloudera mise sur l'hybridation, la souveraineté et l'ouverture avec ses solutions supportant les solutions open source Iceberg et Polaris.
Alors que l'idée d'une domination exclusive du cloud public se ratatine, la réalité de l'hébergement des données évolue vers des architectures hybrides. Les entreprises naviguent entre des contraintes réglementaires renforcées (RGPD, Dora ou NIS2), une pression accrue sur la performance et l'exigence de souveraineté. Sophie Papillon, vice-présidente France & Afrique du Nord chez Cloudera, observe ainsi : « On voit que les choses bougent beaucoup parce qu'il y a beaucoup d'incertitudes géopolitiques et donc les entreprises se posent la question de l'hybridation. » Ce climat de changement conduit ŕ l'émergence de plateformes capables de s'adapter aux besoins complexes des entreprises, en offrant une réelle flexibilité entre environnements sur site, cloud privé ou multicloud public. Acteur Hadoop historique, avec Mapr et Hortonworks, Cloudera s'est affranchi des limitations des anciens formats de tables afin de se tourner vers les nouveaux usages (multi-cloud, gouvernance, IA, conformité, etc.) en misant sur les solutions open source Iceberg et Polaris (voir encadré). Si Hadoop définit une plateforme complčte avec stockage (HDFS), calcul (MapReduce, puis Spark), et un catalogue de tables (Hive), Iceberg remplace les formats de tables historiques (Hive ou ORC) pour exploiter les męmes clusters de stockage ou des services cloud, mais avec des capacités plus avancées et une bien meilleure intégration multi-cloud et multi-moteurs avec les data lake house. Cette transition est doublée d'une quęte d'ouverture et d'anti-enfermement technologique. Sophie Papillon précise : « Le principe du data lake house est devenu une espčce de standard important pour les entreprises. Trčs tôt, Cloudera a misé sur le format Iceberg qui permet une interopérabilité et une flexibilité avec le traitement de trčs grosses données, ce qui est extręmement important. » L'adoption du format ouvert Iceberg s'inscrit donc au coeur de la stratégie de la société, garantissant l'indépendance des clients face aux restrictions des solutions propriétaires et renforçant l'agilité dans la gestion et l'exploitation des données ŕ grande échelle.
Accompagner la migration et l'optimisation
La capacité ŕ accompagner la migration depuis des data warehouse historiques comme Teradata et ŕ optimiser les infrastructures représente un enjeu technique déterminant pour les entreprises souhaitant maîtriser leurs coűts. Denis Fraval-Olivier, solutions engineer director EMEA South chez Cloudera, explique que « les clients qui vont faire de la transformation, qui vont prendre du legacy data warehouse et qui vont le transformer pour le mettre dans des solutions type modernes, data lakehouse, vont le faire pour des raisons de coűt, pas pour des raisons techniques. » Dans de nombreux cas, la migration n'est d'ailleurs pas totale. Cloudera privilégie une logique de fédération et d'interopérabilité, oů chaque client décide de maintenir ou de déplacer certaines données en fonction de son contexte. Cette approche facilite une transition progressive, évitant les projets interminables et coűteux souvent associés aux migrations traditionnelles, tout en permettant une exploitation combinée des nouvelles et anciennes architectures. Denis Fraval-Olivier souligne également : « On va utiliser les moteurs de requętes les uns pour aller requęter des données qui sont stockées chez les autres et vice versa. Et lŕ, c'est nouveau : on n'a pas cet effort de transformation. » Ce mode de fonctionnement, permis par l'adoption de standards ouverts, permet d'interroger et d'analyser la donnée lŕ oů elle est sans recourir systématiquement ŕ la migration. Avec cet atout, Cloudera offre non seulement une modernisation de la plateforme, mais aussi une optimisation tangible des coűts et une plus grande maîtrise du patrimoine informationnel.
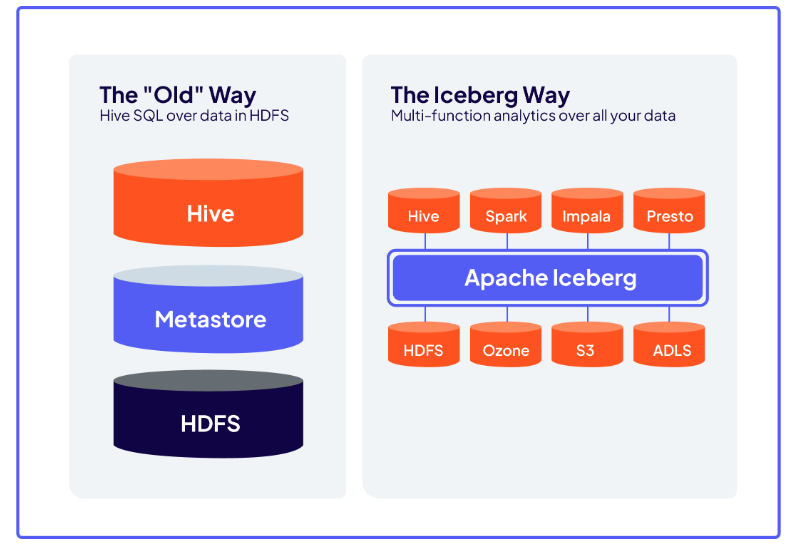
En misant sur Iceberg, Cloudera réconcilie les anciennes plateformes comme Hadoop avec les architectures cloud. (Crédit Cloudera)
Sous le capot, Cloudera Data Platform intčgre un ensemble complet d'outils open source pour l'ingestion (Nifi, Kafka ou Flink), l'analyse, la gouvernance et la sécurité centralisée des données. Cette architecture s'adapte aussi bien ŕ des environnements cloud, hybrides ou sur site, au plus prčs des exigences de souveraineté des clients. Selon Denis Fraval-Olivier, « le choix du format Iceberg joue ici un rôle crucial, car il permet aux clients d'avoir la liberté de choix des composants logiciels, ainsi que du choix de l'infrastructure, que ce soit sur site ou dans le cloud, répondant ainsi ŕ une forte demande de solutions hybrides. » Ainsi, la tarification proposée par Cloudera, fondée sur l'infrastructure consommée et non sur le « token », favorise l'adoption de l'intelligence artificielle ŕ grande échelle sans limiter les usages au sein de l'entreprise.
Iceberg et Polaris au service de la donnée
L'émergence rapide de solutions open source comme Iceberg et Polaris est en passe de transformer durablement la gestion des données et l'architecture des plateformes hybrides. Iceberg se présente comme un format de table open source conçu pour le big data, intégrant nativement des fonctionnalités avancées telles que le support des transactions ACID, la gestion de l'évolution du schéma, la possibilité de revenir ŕ une version antérieure (time travel) et la compatibilité avec de nombreux moteurs analytiques tels que Spark, Trino, Flink ou Presto. Ce format, né chez Netflix et Apple avant d'ętre confié ŕ la fondation Apache, a su séduire des géants du numérique comme Airbnb, LinkedIn ou Adobe, notamment en raison de la gouvernance communautaire et de l'interopérabilité qu'il procure. Denis Fraval-Olivier affirme ainsi que « le concept de partage, il transforme l'industrie de la donnée. Avec un standard comme Iceberg, on élimine l'effort traditionnel de migration et on permet de requęter la donnée lŕ oů elle se trouve, fédérant différents environnements, anciens ou récents. » Il rappelle aussi : « Aujourd'hui, on utilise Iceberg pour permettre le portage des traitements tout en documentant les flux, ce qui optimise la migration et réduit drastiquement la complexité technique. » Grâce ŕ cette approche, la fédération des silos de données et la coexistence entre sources anciennes et récentes deviennent effet, ouvrant la voie ŕ une véritable agilité des architectures.
Parallčlement, Polaris s'impose comme un catalogue open source dédié ŕ l'indexation et ŕ la gouvernance des tables Iceberg. Ce projet, lancé par Snowflake en partenariat avec un écosystčme varié incluant Google, AWS, Dremio, Salesforce ou Alation, facilite la gestion des métadonnées en s'appuyant sur les spécifications REST d'Iceberg, permettant ainsi la lecture et l'écriture des données en mode cross-moteur sans verrouillage propriétaire. « Iceberg est un standard au niveau du format de table de données. Mais au niveau du data catalogue, il n'y a pas encore de standard qui a émergé. Polaris, aujourd'hui, permet cette mutualisation, évitant l'enfermement et préparant l'essor d'une interopérabilité totale, » analyse Denis Fraval-Olivier. Pour les entreprises, l'enjeu est de s'assurer que chaque table puisse ętre facilement découverte, interrogée et sécurisée selon les besoins, sans dépendre d'un fournisseur unique ou subir les obstacles ŕ la portabilité. L'alliance d'Iceberg et de Polaris s'avčre ainsi déterminante : elle garantit l'interopérabilité entre infrastructures hétérogčnes, assure une gestion avancée des métadonnées pour répondre aux défis de la gouvernance et des réglementations, et bénéficie d'un fort soutien communautaire qui la rend pérenne et évolutive. Denis Fraval-Olivier insiste d'ailleurs sur la dimension ouverte et collaborative du projet : « Polaris, c'est l'expérience d'un acteur fermé comme Snowflake qui s'associe ŕ des acteurs ouverts comme Cloudera pour promouvoir une réelle interopérabilité. Nous avons voulu montrer qu'on n'est pas enfermé dans un monde : tout est ouvert. » Grâce ŕ son engagement précoce dans l'intégration d'Iceberg et de Polaris, Cloudera offre aujourd'hui aux entreprises une trajectoire de modernisation souple et évolutive. L'enjeu n'est plus simplement l'adoption de nouvelles technologies, mais de garantir la pérennité, la flexibilité et la liberté d'usage des données.














Suivez-nous