")
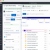
Evolution des signalements sur Downdetector suite ŕ la panne AWS Dynamo DB. (crédit : Downdetector)
Une panne de résolution DNS du point de terminaison de l'API DynamoDB en Caroline du Nord affecte une soixantaine de services du fournisseur de cloud américain. Avec pour effet de provoquer des dysfonctionnements et des indisponibilités en cascade dans le monde, chez Perplexity, Asana, Bank of Scotland, entre autres.
Une panne DynamoDB d'AWS en Caroline du Nord perturbe depuis le début de la matinée de nombreux sites et services web mondiaux. « Nous avons identifié une cause potentielle des taux d'erreur pour les API DynamoDB dans la région US-East-1 (Caroline du Nord). D'aprčs notre enquęte, le problčme semble ętre lié ŕ la résolution DNS du point de terminaison de l'API DynamoDB dans US-East-1 », a expliqué AWS ŕ 02h01 (11h01 heure française). Pour rappel ce service de base de données NoSQL est trčs utilisé par les fournisseurs de sites et services web ayant des besoins importants en matičre de récupération, stockage et traitement d'importants volumes de données.
Ce problčme affecte également d'autres services du fournisseur américain dans cette région. En quelques heures, leur nombre n'a cessé d'augmenter pour atteindre vers 11h30 une soixantaine incluant database migration service, identity and access management, cloudwatch, polly, cloudfront, elastic compute cloud et kubernetes service... Avec pour conséquences des dysfonctionnements et interruptions d'un grand nombre de sites et services web mondiaux reposant sur ces solutions. « Perplexity est actuellement indisponible. Le problčme provient d'un dysfonctionnement d'AWS. Nous travaillons ŕ sa résolution », a expliqué Aravind Srinivas, le CEO du service. Des banques en ligne ont également été perturbées comme Lloyds Bank, Halifax et Bank of Scotland, de męme que des services divers comme Asana, Coinbase, Snapshat, Vodafone... Aux États-Unis, plus de 20 000 signalements « potentiellement liés aux problčmes AWS » ont été effectués ces derničres heures indique Downdetector.
Des premičres mesures d'atténuation en place
La résolution de cet incident est en cours. « Nous avons appliqué les premičres mesures d'atténuation et observons les premiers signes de rétablissement pour certains services AWS affectés. Pendant cette période, les requętes peuvent continuer ŕ échouer pendant que nous travaillons ŕ la résolution complčte du problčme. Nous recommandons aux clients de réessayer les requętes qui ont échoué. Męme si les requętes commencent ŕ aboutir, il peut y avoir une latence supplémentaire et certains services auront un retard ŕ rattraper, ce qui peut prendre plus de temps pour ętre entičrement traité », a fait savoir AWS ŕ 02h22 (11h22 heure française). Et d'indiquer 5 minutes plus tard qu'il constatait « des signes significatifs de reprise ».














Suivez-nous